
こんにちは、てつです!
前回は、Grafanaを導入してCPU、メモリ、ディスク、ネットワークの状況を1枚のボードに集約し、ひと目で「異常なし!」と判断できるようにしましたね!
ただ画面を見ないと異常気づけない状態でした。これでは画面の前で張り付いていないと異常に気づけないです(笑)
なので今回は、、世界中のエンジニア現場で使われているSlackを使い、Grafanaから「サーバーの以上(アラート)」を自動で受け取るシステムを構築していきます!
関連記事は以下に掲載しておきます!



構築ステップ
まずアカウントを持ってない方はこの時点で作っておいてください!では手順を説明します!
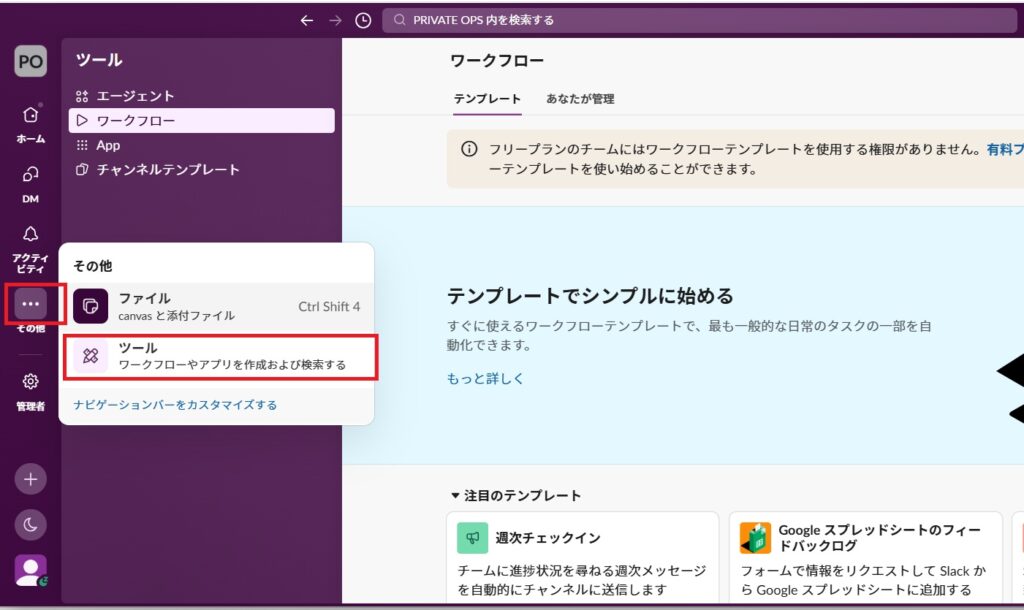
1.Slack側で「受付窓口(Incoming Webhook)」を作る
- Slackに「外部からメッセージを投げ込める専用のURL」を発行してもらいます。
2.Grafana側で「連絡先(Contact points)」を設定する
- Grafanaに対して「何かあったら、さっき作ったSlackのURLにメッセージを投げて!」と登録します。
3.「通知ルール(Alerting rules)」を設定する
- 「CPU使用率が〇〇%を超えたら」「メモリ空き容量が〇〇を下回ったら」という、アラートを発火させる条件(しきい値)を決めます。
4.わざと負荷をかけて「テスト通知」を飛ばす
- 実際にアラートがSlackに届くか、エビデンス(証拠)を掴みます。
Slack側で「受付窓口(Incoming Webhook)」を作る
まずはSlack側で、Grafanaからのデータを受け取るための専用URL(Webhook URL)を発行します!
1.Slackのブラウザ版またはアプリを開き、通知を飛ばしたいワークスペースに移動します。
2.通知専用のチャンネル(例:#server-alert など)を新しく作っておくと管理が楽です。
3.Slackの「App ディレクトリ」または設定画面から Incoming Webhooks というアプリを検索して追加します。
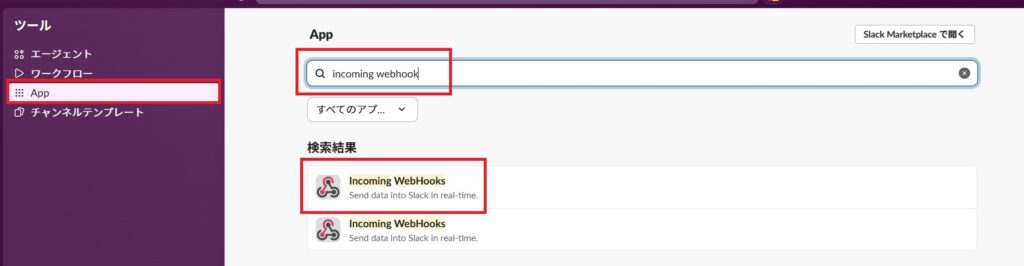
4.「チャンネルへの投稿」で先ほど作ったチャンネルを選択し、「Incoming Webhook インテグレーションの追加」をクリックします。
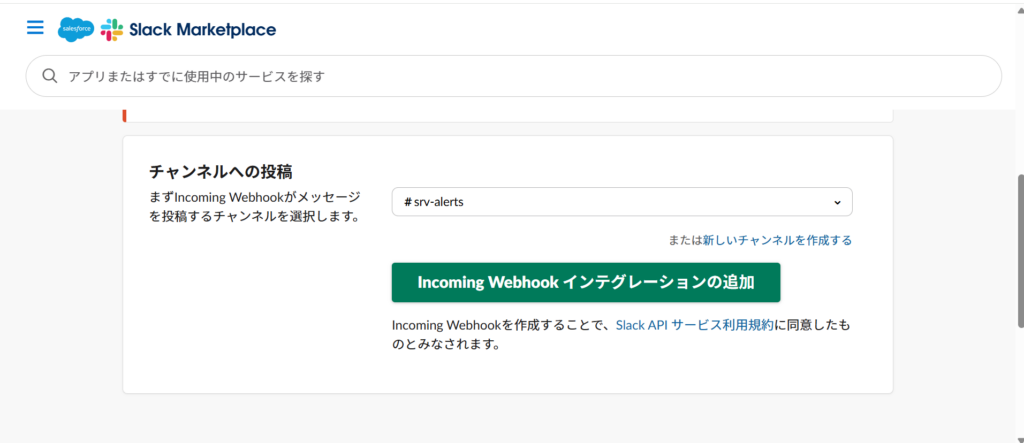
5.画面に表示される Webhook URL(
で始まる長いURL)をコピーして、メモ帳などに控えておきます。

※これは他人に公開しないように気を付けてください。
Webhook(ウェブフック)とは?
何をしているか: Slackの中に「外部のシステムが自由に文字を投げ込める、専用のポスト(URL)」を設置しています。
なぜ必要か: 通常、Slackに文字を書き込むには人間がログインしてキーボードを叩く必要がありますが、この専用URLに向けてデータを送信(HTTP POST)すると、プログラムやツールが人間の代わりに自動でメッセージを投稿できるようになるためです。
Grafana側で「連絡先(Contact points)」を設定する
次に、前回完成させたGrafanaの画面に戻り、先ほどのSlackのポストの場所を教え込みます!
1.Grafanaの左メニューから Alerting(アラート) > Manage Contact pointsをクリックします。
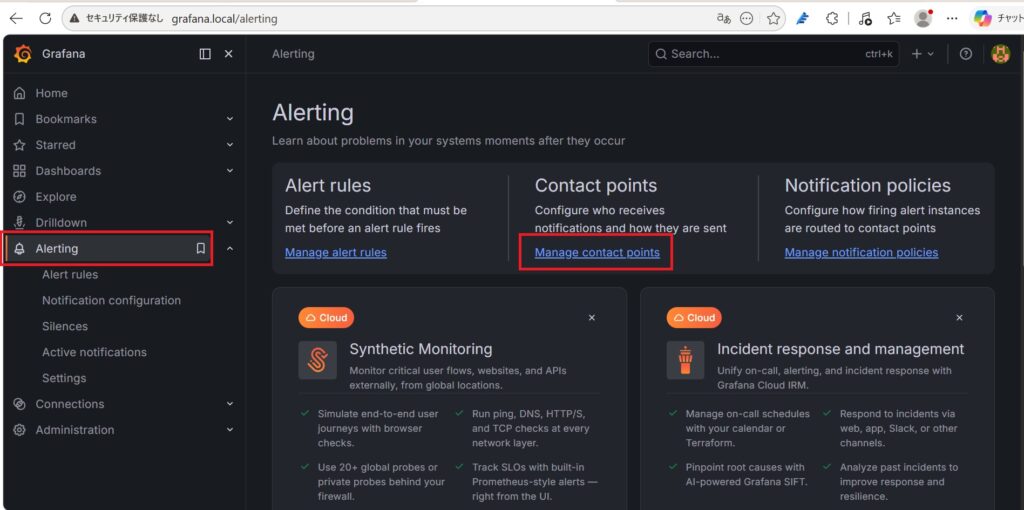
2.画面右上にある + New contact pointをクリックします。
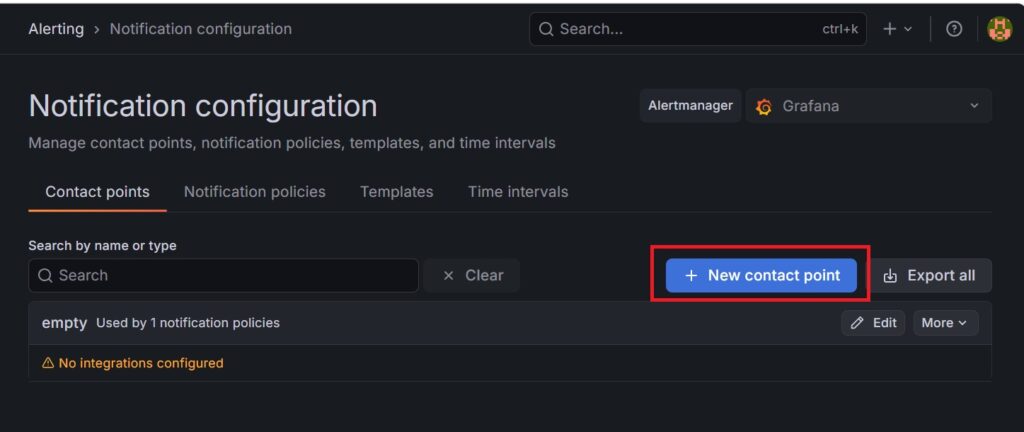
3.以下の通りに入力・設定します。
- Name:
Slack-Alert(分かりやすい名前でOK) - Integration: プルダウンから
Slackを選択 - Webhook URL: ステップ1でコピーしたSlackのURLをそのまま貼り付け
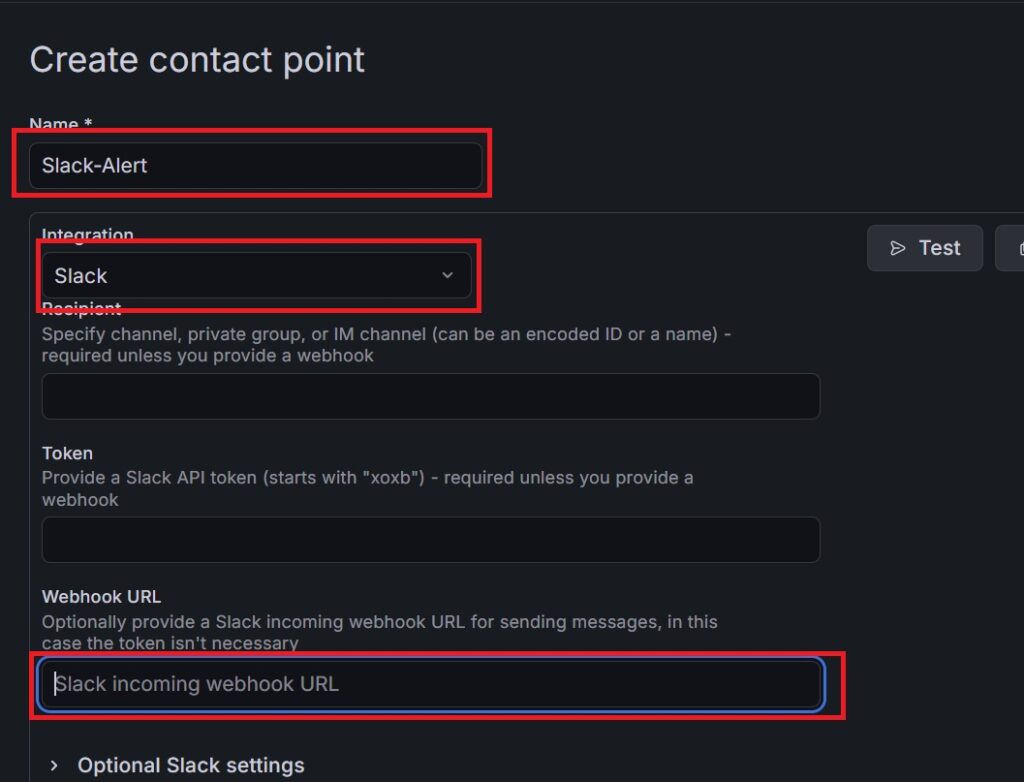
4.入力したら、画面下部にある Test ボタンを押してみてください。Slackのチャンネルに「[Alerting] Test Alert」と通知が飛んでくれば大成功です!

5.確認できたら Save contact point をクリックして保存します。
「通知ルール(Alerting rules)」を設定する
今回は、最も実用的な「CPU使用率が高すぎる場合にアラートを出す」と「サーバー停止時(疎通不可)にアラートを出す」というルールを作成します。
CPU使用率アラート設定手順
1.Grafanaの左メニュー Alerting > Alert rules をクリックします。
2.右上の + New alert rule をクリックします。
3.以下の4つのセクションを順番に設定していきます。
3-1. Enter alert rule name: High CPU Usage など分かりやすい名前を入力。
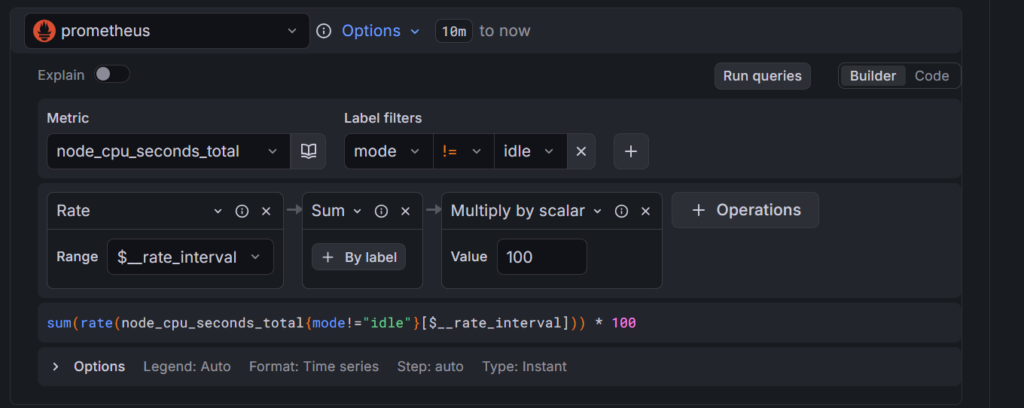
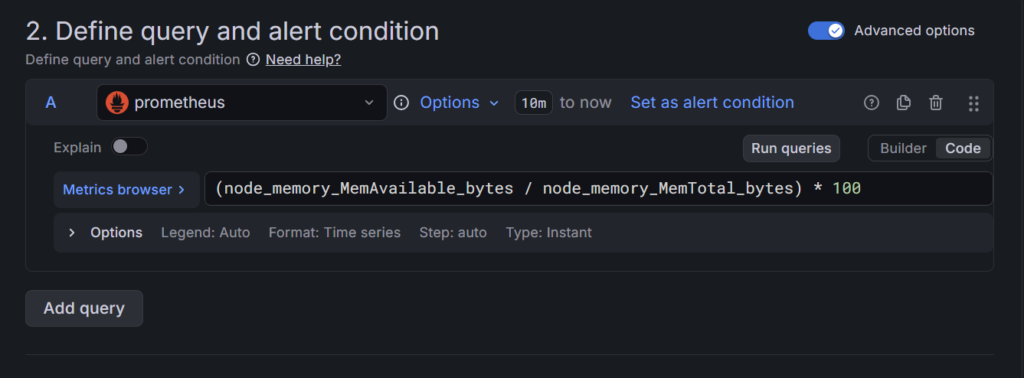
3-2. Define query and alert condition:
Metric: node_cpu_seconds_total を選択します。
Label filters:
右側の + ボタンを押し、以下のフィルタを追加します。
・Label: mode
・Operator: != (等しくない)
・Value: idle
次に、バラバラのデータを「使用率」に変換します。+ Operations ボタンを押し、以下の順で追加してください。
・Range functions > rate: 「秒あたりの変化量」に直します。
・Aggregations > sum: 全コアの合計を出します。
・Binary operations > Multiply by scalar: 数値を 100 にします(%表記にするため)。
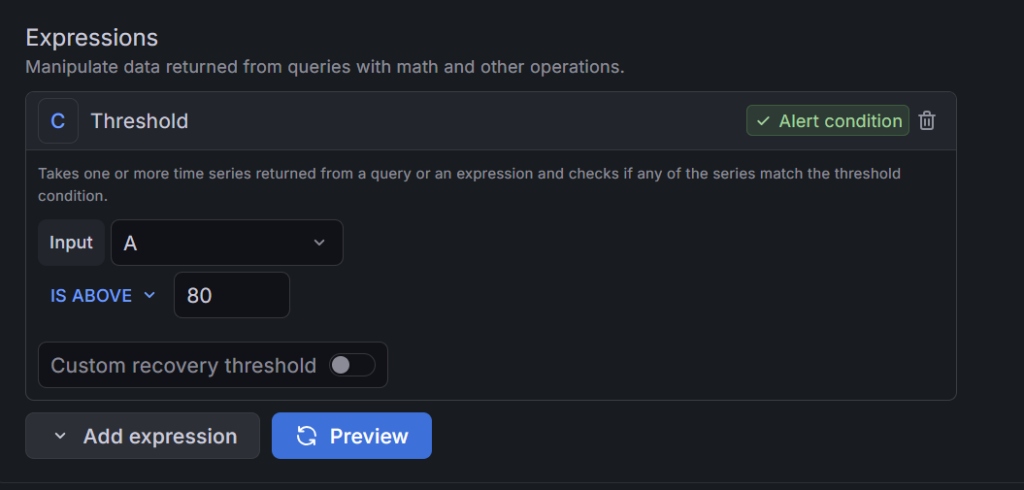
下記画像のように設定できてれば大丈夫です!
- Expressions >
Thresholdの設定をIS ABOVE 80に設定
※Expressionsがない場合は「Define query and alert condition」の隣にあるAdvanced optionsがONになっているか確認してください。
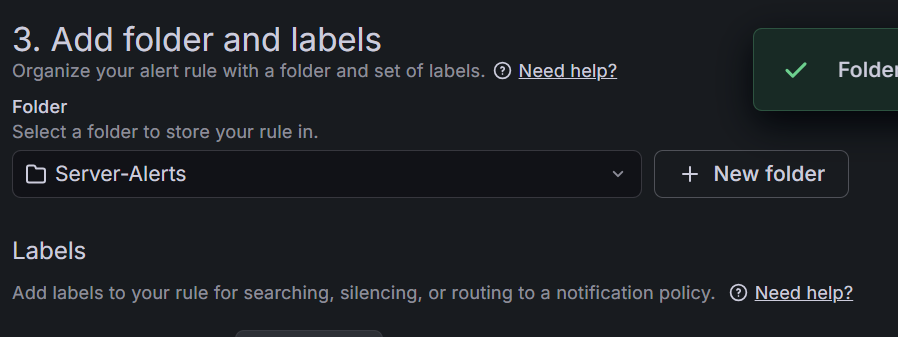
- 3-3. Add folder and labels
+ New folderを選び新しく Server-Alerts と入力して作成します。
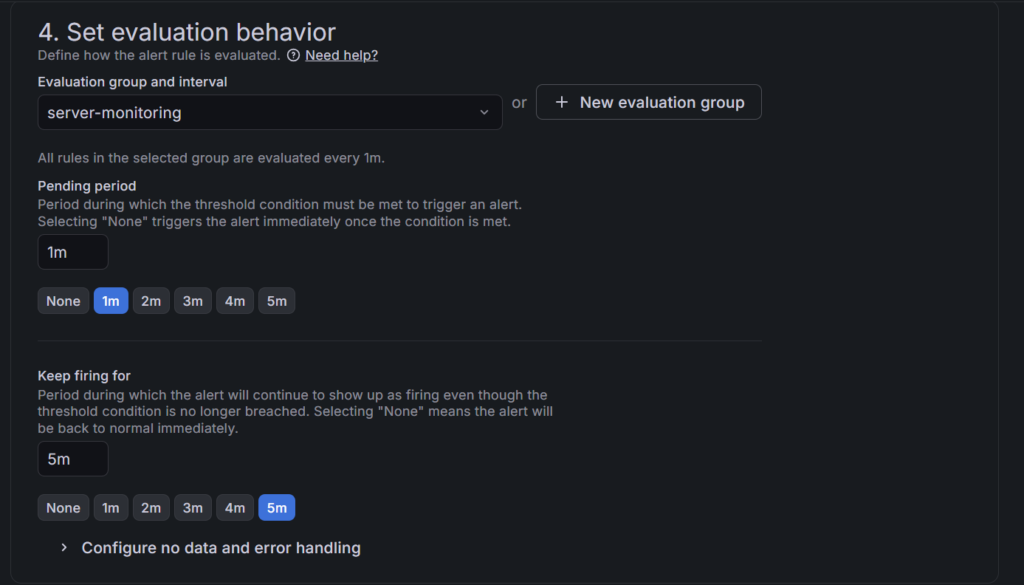
- 3-4. Set evaluation behavior:
- New evaluation groupをクリックし、新しいグループ名を入れる
- Evaluate every:
1m(1分ごとにチェック) - For:
5m(5分間連続で条件を超えたら発火) - ※「一瞬だけ80%を超えた」程度の誤検知を防ぐためのプロの知恵です。
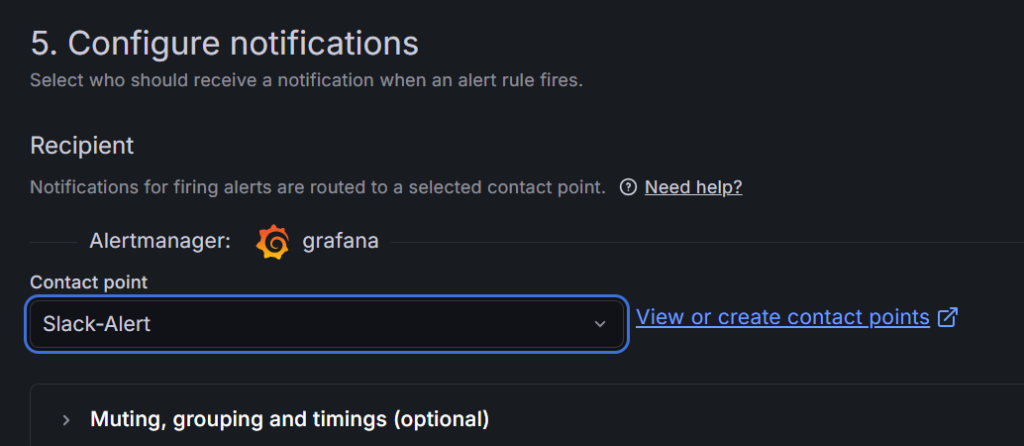
- 4. Configure notifications:
Contact pointに、先ほどステップ2で作ったSlack-Alertを選択します。
4.最後に一番下の Save をクリックして保存します。
サーバー停止アラート設定手順
CPU使用率アラート設定手順と同様に、New alert rule から設定してきます!
設定内容は以下のようにしてください!
・Metric: up
・Label filters: job = node_exporter
・Operations: なし(そのままでOK)
・Threshold: IS BELOW 1(1を下回ったら=0になったら)
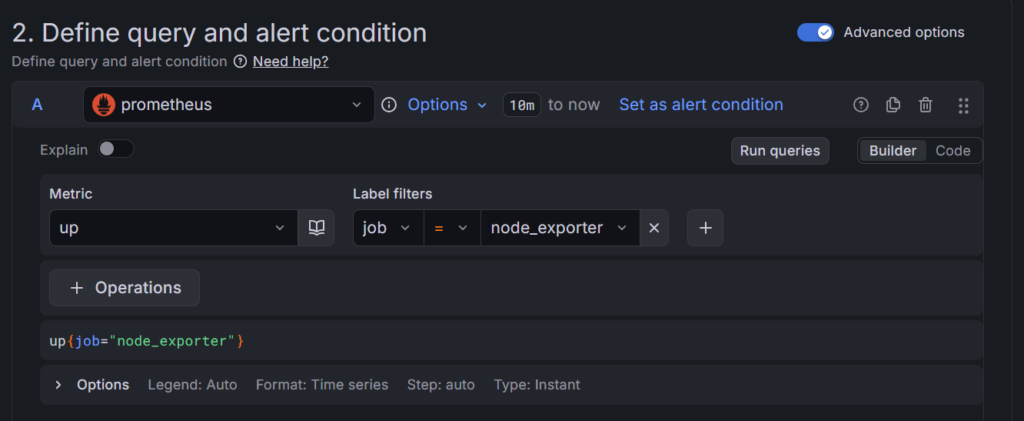
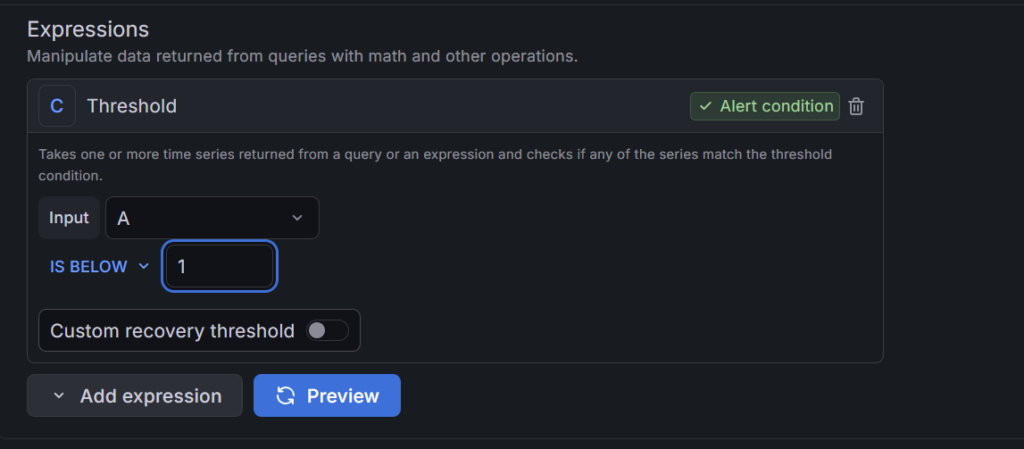
ロジック: Prometheusの up という指標は、正常なら 1、異常なら 0 になります。そのため「1未満」になったらアラート、というシンプルな設定で「サーバーが死んだ」ことを検知できます。
ディスク容量不足アラート
「ログが溜まってパンクする」のを防ぎます。
・Metric: node_filesystem_avail_bytes(空き容量)
・Label filters: mountpoint = / (OSが入っているメインの場所を指定)
→OSが入ってるところはCodeモードで「node_filesystem_avail_bytes」と式のところに入力し、「Run queries」を実行、出てきたTableの右端の方にあります。
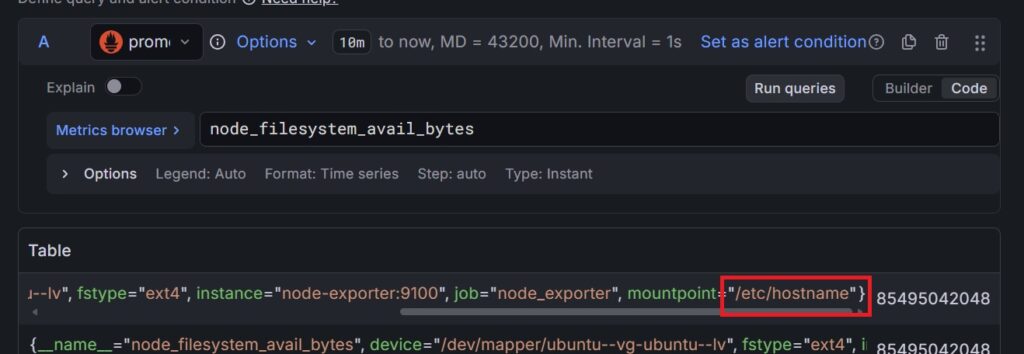
・Operations:
- 1.
Binary operations>/:node_filesystem_size_bytes(全容量)で割る 2.Binary operations>*:100(パーセントにする)
・Threshold: IS BELOW 10(空きが10%を下回ったら)
※Builderモードでやる場合少し工夫が必要で手順が煩雑になるので、下記の式をcodeモードで記述する方法もあります。
avg((node_filesystem_avail_bytes{fstype="ext4"} / node_filesystem_size_bytes{fstype="ext4"}) * 100)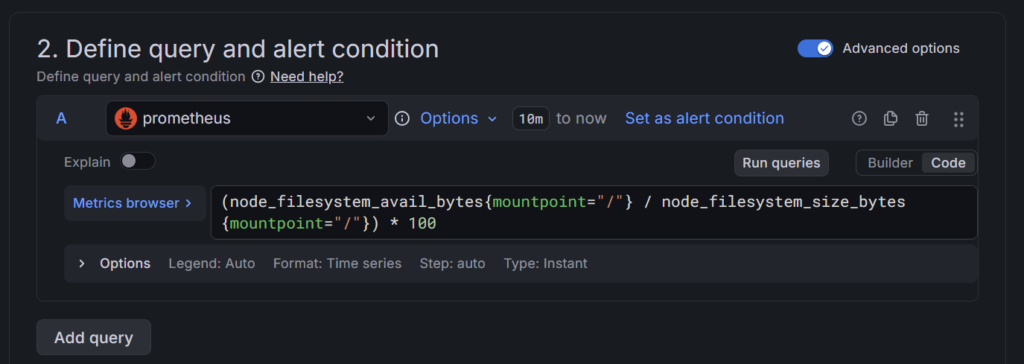
ロジック: 「空き容量 ÷ 全容量」で「空きの割合」を出します。これが10%を切ったら、掃除を始める合図です。
メモリ枯渇アラート
「動きが激重になる・アプリが落ちる」のを防ぎます。
Builderモードだと標準機能では設定しずらいので、下記式をCodeモードで入れてください。
(node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100何をしているか: 「今使えるメモリ」を「積んでいる全メモリ」で割り、100を掛けています。
なぜこの式か: メモリは「使用済み」を計算するよりも「あとどれだけ余裕(Available)があるか」を監視する方が、システムのパンクを未然に防ぐ目的(監視の本質)に合致するためです。
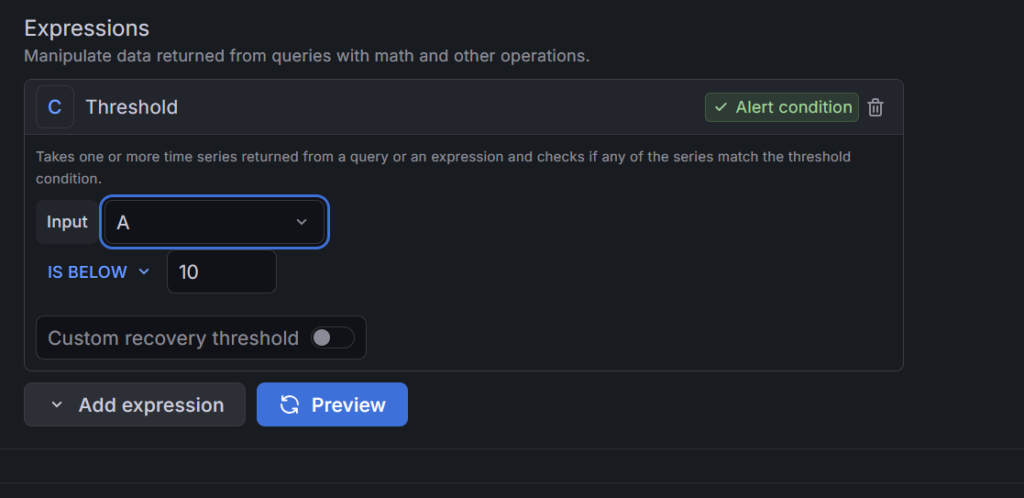
・Threshold: IS BELOW 5(空きが5%を下回ったら)
ロジック: メモリもディスクと同様に「残量」を監視します。メモリはギリギリまで使われることが多いので、5%〜10%くらいを閾値にするのが一般的です。
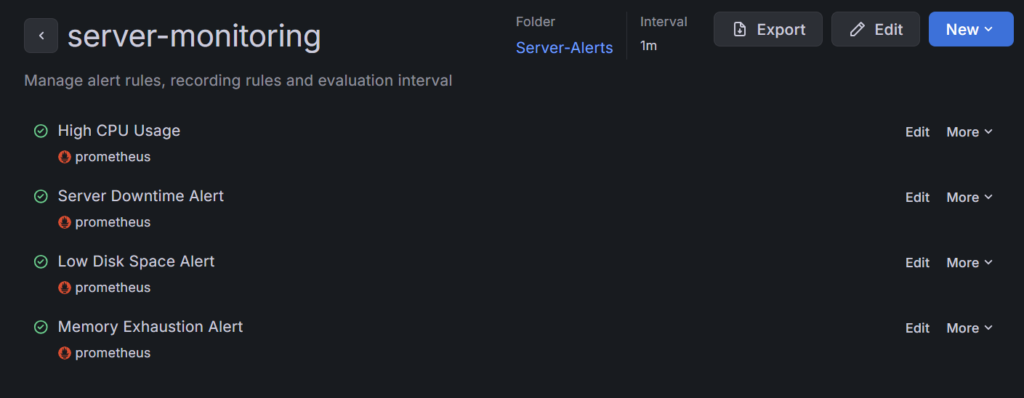
上記の作業がすべてできたら下記の画像のようになると思います!いよいよ監視体制が盤石になってきた感じですね!
最後の仕上げと「テスト」
最後に「本番テスト」をやっていきます!ドキドキしますね!
死活監視のテスト
サーバーの心臓部を止めて、Grafanaが「事件」を検知するか試します。
まず、SSHでサーバーに入り、Node Exporterを停止します!
sudo docker compose stop node-exporter
Grafanaのアラート画面で、緑のチェックが 赤色に変りましたね。
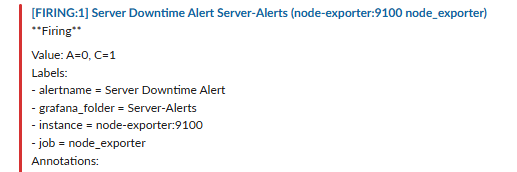
Slackに [FIRING] 通知が届きました!障害通知成功です!
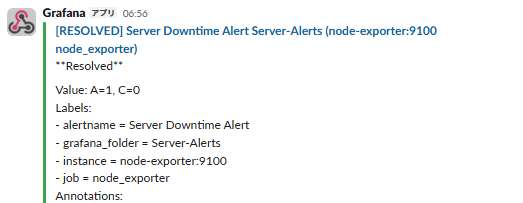
復旧していきます。
sudo docker compose start node-exporter で戻し、[RESOLVED](緑の通知)が来るまでをセットで記録します!

成功ですね!次に移りましょう!
CPU負荷テスト
意図的に計算負荷をかけて、閾値を超えさせます!
以下の「負荷をかけるコマンド」を打ちます。
yes > /dev/null &(※1分ほど放置して通知が来たら、 killall yes で止めてください)
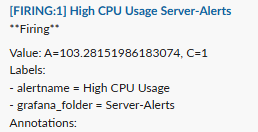
通知が来たのでコマンドを実行して止めます。
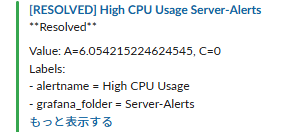
復旧も検知したので切り戻しも完了です!
ディスク・メモリのテスト
これらは実際にパンクさせると復旧が面倒なので、「設定(しきい値)をいじって、今のアラートをわざと発火させる」方法でテストしていこうと思います!
アラートのEdit画面に行き、Thresholdを現在の値より厳しくします。
- 例:ディスク空き容量が81%なら、
IS BELOW 90に一時的に変更。
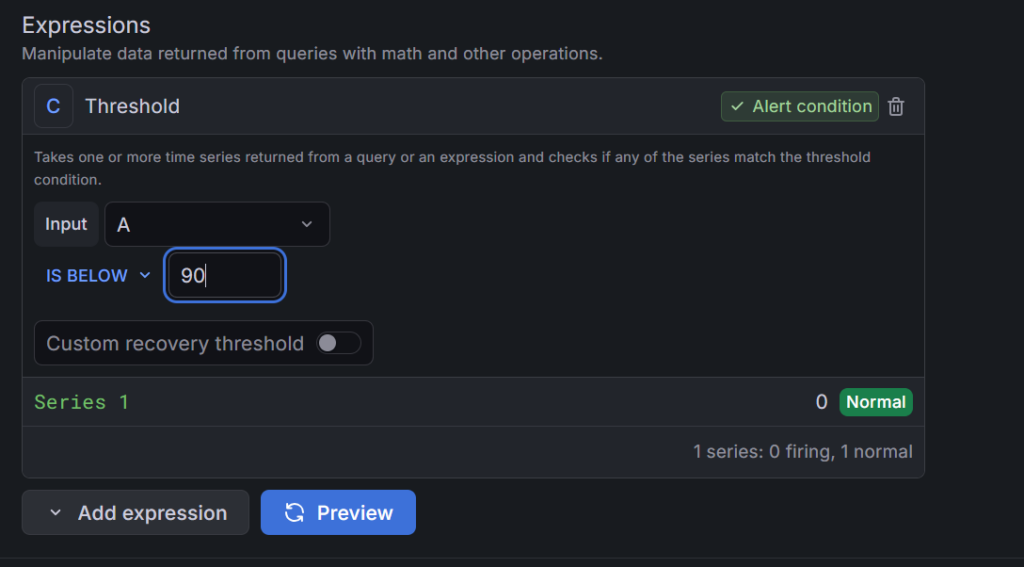

通知来ましたね!これで成功です!
あとは設定を戻して、復旧を検知したら完了です!
メモリの方も同様の手順でやればよいので今回は省かせていただきます。
これで全作業終了です!
まとめ
お疲れさまでした!4回にわたるサーバーの監視体制の構築を見届けてくださりありがとうございました!
「最初はただの数字の羅列だったGrafanaのグラフ。
でも、わざと負荷をかけ、自分のスマホに『[FIRING]』と通知が飛んできたとき、このシステムが自分と繋がっていることを実感しました。
監視を作ることは、サーバーをただ動かすことではなく、サーバーの『声』を聞けるようになることです。 これで私の自宅サーバー構築プロジェクト、インフラ編は一つの完成を迎えました。
まだ次回の内容とかは来てないですか。自動化ツールの作成とかAWSを使ったものとかも触れていきたいですね。
X(旧ツイッター)もやっているので、ぜひこんなことやって欲しいなどがありましたら、気軽にDMなどしていただけると励みになります。
また次回お会いしましょう!ありがとうございました!


コメント