
こんにちは、てつです!
今回から4回にわたって自宅サーバーの監視及び通知体制を確立していこうと思います!
「知らない間にサーバーが止まっていた」「気づかないうちに負荷がかかって壊れそう」という不安があると思います。というか僕は不安です(笑)
なので、24時間365日監視でき、かつサーバーの健康状態を見える化し、そして異常を検知したら通知するという体制を作ります!
自宅サーバーは構築したけど、自分サーバーの状態を知る手段がない人などは是非これからの第4回わたる連載を見て頂ければと思います。
今回この監視体制を導入するサーバーについては過去に記事で投稿しているものになりますので、下記リンクよりご参照ください。




全体のロードマップ
第4回にわたって構築していきますので、ここ一回全体像を共有しておこうと思います!
【第1回:計測器の設置】
- まずは体温計を脇に挟むように、データを測る道具(Node Exporter)を置く。
【第2回:記録係の採用】
- 測った数値をノートに記録し続ける担当者(Prometheus)を雇う。
【第3回:モニターの設置】
- 記録された数値を、誰が見ても一瞬でわかるモニター(Grafana)に映し出す。
【第4回:緊急通報の設定】
- モニターに異常が出たら、即座にあなたのスマホ(Slack)へ電話を鳴らす
第1回目では、サーバーの状態を外部から読み取れるようにします。
そこで使うツールがNode Exporterです。
サーバーは通常、ターミナルにコマンド打たないと見えません。
Node Exporterは、このコマンドを打たないと見えない情報を「特殊なWebページ」として公開します。
そして、第二回で導入するPrometheusがこの情報を読み取る係となります。
Node Exporterが発信している「今のCPUは10%です」という一瞬の情報を、Prometheusが「1分前は5%、今は10%…」と時系列で記録していきます。
これにより、「夜中にだけ負荷が上がっている」といった過去の傾向を後から分析できるようになります。
第3回は、Prometheusが溜めた大量の数字を、美しいグラフやパネルとして画面に映し出すGrafanaというツールを導入していきます。
第4回では、Grafanaが異常を検知した瞬間、Slackへ緊急メッセージを飛ばす仕組みを作っていきます。
「CPUが100%に張り付いた」「ディスクの空き容量が残り10%を切った」といった条件(しきい値)を決めておき、それを超えたら自動でSlackへ通知させます。
全4回の流れはなんとなくわかりましたかね?さっそく第1回のNode Exporter導入をやっていきましょう!
準備:ディレクトリの作成
導入するために前々回構築したサーバーのディレクトリに管理フォルダを作っていきます。
設定ファイルなどは今後増えていくので、管理用のフォルダだけ先に作っておきます。
下記コマンドを実行します。
# server-ops ディレクトリに移動(パスはご自身の環境に合わせてください)
cd ~/server-ops
# 監視設定を入れるためのフォルダを作成
mkdir -p monitoring/prometheusここら辺はちゃちゃっとやって次移りましょう!いよいよ導入です!
ロジック:設計図(docker-compose.yml)への追記
既存の docker-compose.yml をエディタ(nanoやvim、VSCodeなど)で開き、services: の段落の最後に以下のコードを追加します。
将来的にPrometheusとNginx Proxy Manager(NPM)を連携させて、監視画面を独自ドメインで公開したくなった際、1つのファイルにまとまっていると設定が劇的に楽になるので今回は追記する形でやっていきます。
※万が一監視ツールの設定ミスでコンテナが不安定になっても、メインの通信を担うNPMには影響が出ないようにしておくのが、セキュリティ意識の高い設計って考え方もありますのでここら辺は自分のサーバーの用途によって変更してください。
# --- 監視システム:第1回 Node Exporter ---
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
restart: always
# サーバー本体の情報を読み取るための設定(これがないとコンテナ内の情報しか見えません)
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
# 9100番ポートで外部(Prometheusやブラウザ)に公開
ports:
- "9100:9100"なぜこの設定を使ったのか?
volumesの3行: Linuxサーバーの「心臓部(/procや/sys)」を、コンテナの中から「読み取り専用(ro)」で覗き見するための設定です。これがないと、サーバー全体のCPU使用率が正しく測れません。
実践:起動とUFWの設定
設定を保存したら、以下のコマンドを順番に打ちます。
# 1. node-exporter だけを狙って起動します(既存のNPMなどは止まりません)
docker compose up -d node-exporter
# 2. UFW(ファイアウォール)で9100番ポートの門を開けます
sudo ufw allow 9100/tcpここまでできたらブラウザで成果を確認しましょう。
例:http://192.168.11.1:9100など
今回の確認結果です!いい感じです!

上記画像のMetricsをクリックすると下記のような画面が出てきます。ここまで来たら成功です!
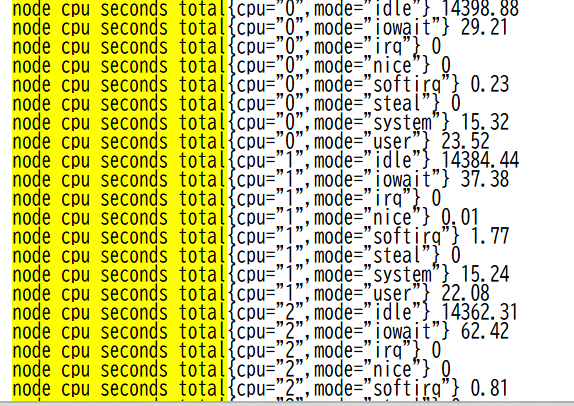
この数字はサーバーの『診断結果レポート』です。安心してください、すべて読むようなものじゃありません!
下の方で必要なやつだけ少し解説しますね。

下記の画像で黄色くなっているところが、CPUがどれくらい働いたかの累積時間です。
四季の画像で黄色くなっているところが、今使えるメモリの空き容量(バイト単位)です。

これらの画像を見てわかったかと思いますが、人間にはめっちゃ読みにくいです。
次回導入する Prometheus(記録係) にとっては、これが最高に読みやすい「大好物なデータ形式」なんです。
詳しいことは次回解説しますね!
最後に
第1回で「データの出しっ放し(垂れ流し)」ができるようになりました。
しかし、今のままではブラウザを閉じればデータは消えてしまい、過去に何が起きたか分かりません。
第2回:【初心者向け自宅サバ監視入門:第2回】Prometheusを立てて監視システムを開始する では、この垂れ流されているデータを、1秒も漏らさず「データベース」に保存する仕組みを作っていきます。


コメント