
こんにちは、てつです!
今回からは、ブログの半自動化の構築過程を記録していこうと思います!
ブログの半自動化といっても、前回までに立ち上げたブログサーバーが外部に公開していないものになるので、ブログの完全自動で不労所得を謳うような記事ではないことご留意お願いします。
では、なぜブログの半自動化をするのか?
それはせっかくブログサーバーを建てたし、なにかを作ってみたいからです!笑
自分が何もしていないのにブログの記事ができてたらテンション上がりませんか?僕は上がります!
とはいっても外部に公開しないとはいえ、人の目を通さずそのまま公開するのは自動化フローとしては良くないので、今回から作るブログの半自動化プロジェクトは下書きまでとさせていただきます。
出来る限り画面のキャプチャは取っていくつもりですが、APIキーや個人アカウントの流出防止のためコードの詳細やbashでのユーザー名などは伏せさせていただきます。
また、私もまだまだ分からない点などが多いため、基本は書籍やAIなどの力を借りていく方針となりますのでよろしくお願いいたします。
関連記事

今回やること
この記事でやることは以下のものになります。
1.GitHubにプロジェクトのリポジトリ作成
2.プロジェクト全体フロー作成
少ないと思いましたか?
実際やること自体は少ないです。しかし、GitHubのリポジトリ作成とプロジェクト全体のフロー作成はとても重要なことです。
順番に説明していきましょう。
GitHubについて
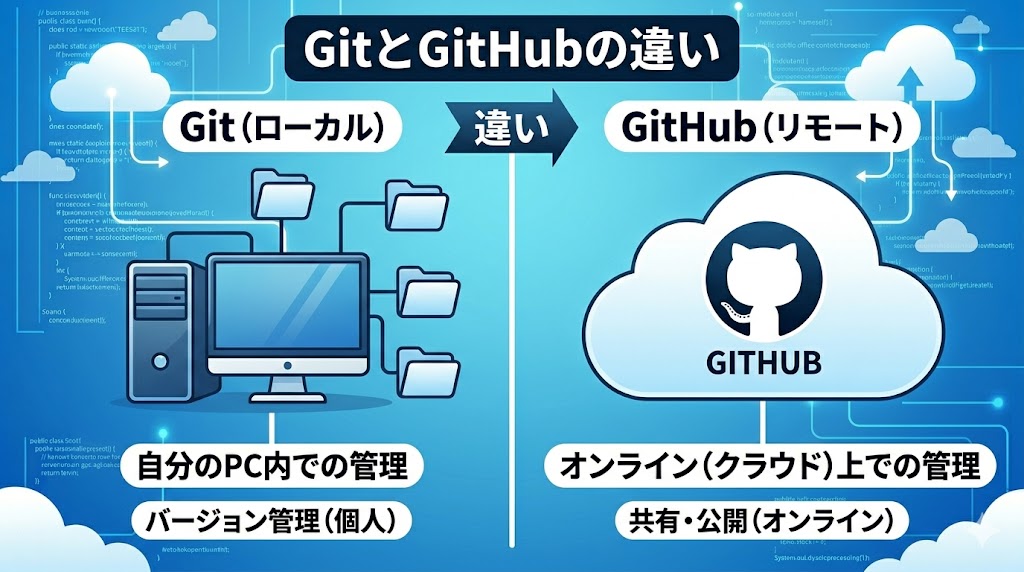
そもそも、GitHub(ギットハブ)とは「プログラムの設計図(コード)を保存し、その変更履歴を管理したり、世界中の開発者と共有・共同作業したりするためのプラットフォーム」のことです。
GitHubの理解については「Git」というツールの理解が必要なのですが、要はバージョン管理ツールという理解をしてくれれば一旦大丈夫です。
では、「Git」と「GitHub」の違いはというと、「Git」が自分のPC内でのみの管理で、「GitHub」はそのデータを「オンライン(クラウド)上で管理するという違いです。
調べると、チーム内での共同開発の拠点となるであったり、コードレビューのリクエストができたりなど様々な便利ポイントが出てきます。
ただ今回は個人開発です。どういう利点があって利用するのか。
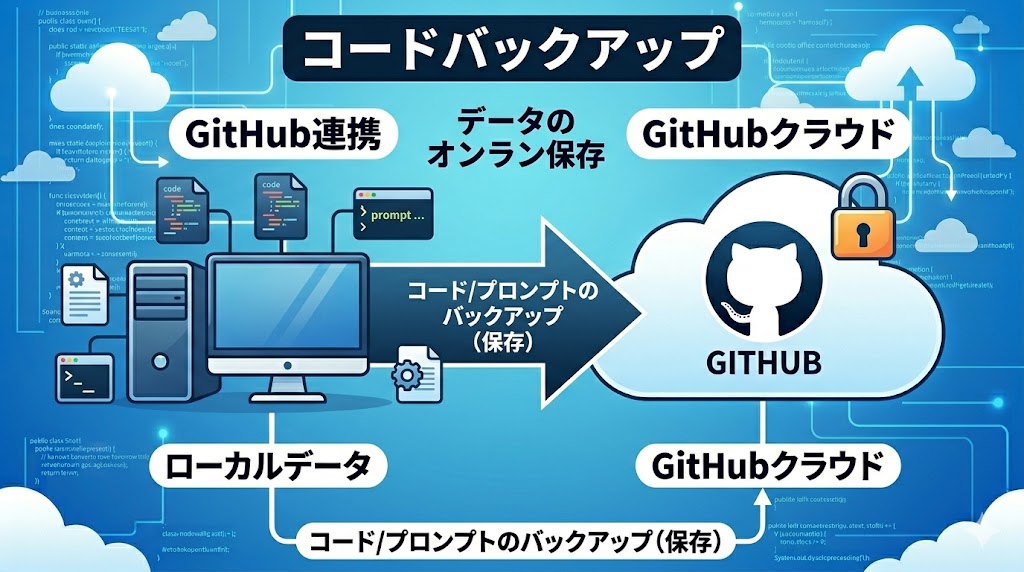
それは、コードやプロンプトのバックアップをオンライン上で保存できる点です。
今回使うサーバーは、これまで記事で書いてきたストレージ容量32ギガ、メモリ4ギガのPCです。
はっきり言って、低スペックもいいところです笑
ここにプロジェクトのデータをすべて保存しておくのは危険すぎます。そのためにバックアップをオンライン上で保管しておくのです。
後これも大きな利点なんですけど、コードやプロンプトの試行錯誤をする上でロールバックできるのがとても便利です。
これはこれからの記事で試行錯誤する段階の時に解説しますね。実際に手こずってる筆者の姿を見たほうが想像しやすいと思うので。
プロジェクト全体の処理フロー作成
いきなりコード書かない理由として、以下の点が挙げられます。
1.「手戻り」を最小限にするため
2.AIへの指示が正確になるため
3.「実装のヌケモレ」を防ぐため
1.「手戻り」を最小限にするため
コードを書き進めた後で「あ、このサービスではこの機能が実現できない」とか「あ、これ必要ないわ」とか「これじゃ実装できない」に気づくと、数日分の作業がムダになるんですよ。
フロー図の段階なら、AIとのフロー図作成段階での修正が可能なので数秒で済みます。
もちろんAIを鵜呑みにして、実装できないということがないようにファクトチェックは必要です。
2.AIへの指示が正確になるため
例えば、「ブログを自動化したい」とAIに頼むより、「まずデータを取得し、次に要約し、最後にWordPressへ投稿するフローの、最初のステップを作って」と頼む方が、AIは精度の高い回答を出してくれますね。
AIは聞いたことには、その時点で最善と思われる回答を提示してきます。ただ、具体的な指示を出さないと自分の意図異なる回答が出力されます。
AIは与えられた情報以上のことは基本出来ません。なので事前に自分で考えるなり、人やAIとブレンインストーミングをするなりして、プロジェクトの全体フローは大まかに決める必要があるのです。
「実装のヌケモレ」を防ぐため
エラーが起きたときの処理(例外処理)や、APIキーの読み込みタイミングなど、頭の中だけでは見落としがちなステップを可視化できます。
前述しましたが、AIにエラーのこと聞く際にもプロジェクトの全体フローを共有しているかどうかでこういった抜け漏れもないように構築していけます。
ただ、ここで完璧なフローを作る必要は必ずしもありません。
というのも、IT開発の世界では「アジャイル」や「プロトタイピング」と呼ばれる進め方が一般的だからです。簡単な流れを下に書いておきますね。
仮のフローを作る: 「たぶんこういう手順でいけるはず」という仮説を立てる。
小さく作る: 1ステップずつAIと作ってみる。
壁にぶつかる: 「このAPI、思ったより制限が厳しいな」といった現実に直面する。
フローを修正する: 現実に合わせて、全体の流れを書き換える。
こんな感じで、まず仮のフローをつくって、うまくいかなかったらフローを修正するという流れにするのが結局は最善のルートだったりします。
なので、あまり気負わずフローを組んでみてください。
修正するというのは失敗ではありません。成功への軌道修正なだけです。やり切りましょう!
次章では実際にGitHubでリポジトリを作成しましょう。
1.GitHubにプロジェクトのリポジトリ作成
この流れで進めていきます。
1.箱(リポジトリ)の準備: GitHubのWeb画面で、名前を決めて空のリポジトリを作成します。
2.通行証(SSH鍵)の作成: サーバー側で、GitHubと安全に通信するための「秘密鍵」と「公開鍵」のペアを生成します。
3.通行証の登録: 生成した「公開鍵」をGitHubに登録し、自分のサーバーからのアクセスを許可します。
4.紐づけと送信: サーバー内のフォルダとGitHubのリポジトリをリンクさせ、コードをアップロード(プッシュ)します。
1.箱(リポジトリ)の準備
さっそくGitHubのリポジトリを作っていましょう。
と言いたいところんですけど、GitHubのアカウント持ってない人はこの時点で作っておきましょう。
下記のリンクから公式サイトへいってGitHubのアカウントをつくっちゃいましょう。
無料版で十分すぎるので、特段理由がなければ無料版で大丈夫です!

アカウントの作成が完了したら、HomeのTop repositoriesの近くにあるNewから新たなリポジトリを作成しましょう。
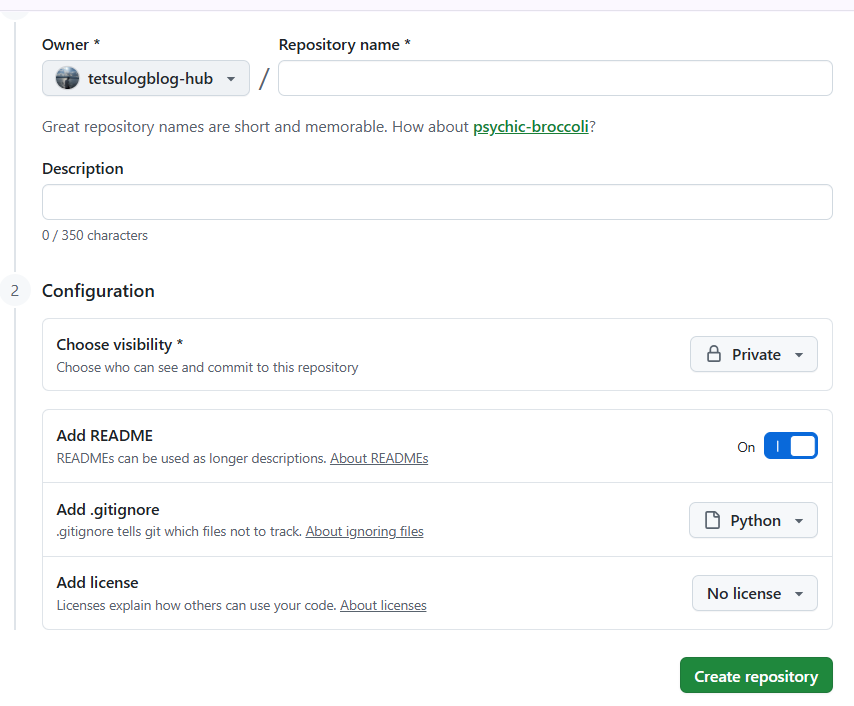
押したら下記のようなところに飛ぶと思うので、リポジトリ名を入れ、自分の用途に合った設定をしてください。
私はリポジトリをプライベートにして、REAMDMEをON、gitignoreにpythonを選択しました。
Create repositoryを押してリポジトリを作成したら次の手順に移ります。
2.通行証(SSH鍵)の作成
そしたら、サーバー側で書いたコードのバックアップをとれる状態を作るために、通信用の鍵生成していきます。
サーバー側で下記コマンドを実行していきます。
ssh-keygen -t ed25519 -C "your_email@example.com"
これを実行したら、Enter file in which to save the key~って聞かれると思うので、Enterを押してください。あと二回くらいこんな感じで聞かれるので全部Enterを押してください。
そしたら、下記コマンドを実行し公開鍵の確認をしましょう。
cat ~/.ssh/id_ed25519.pub
ssh-ed25519~という内容が書いてあるファイルが開いたのではないかと思います。
3.通行証の登録:
上の手順で取得したSSH鍵をGitHubの「Settings > SSH and GPG keys>New SSH key」に貼り付けましょう。
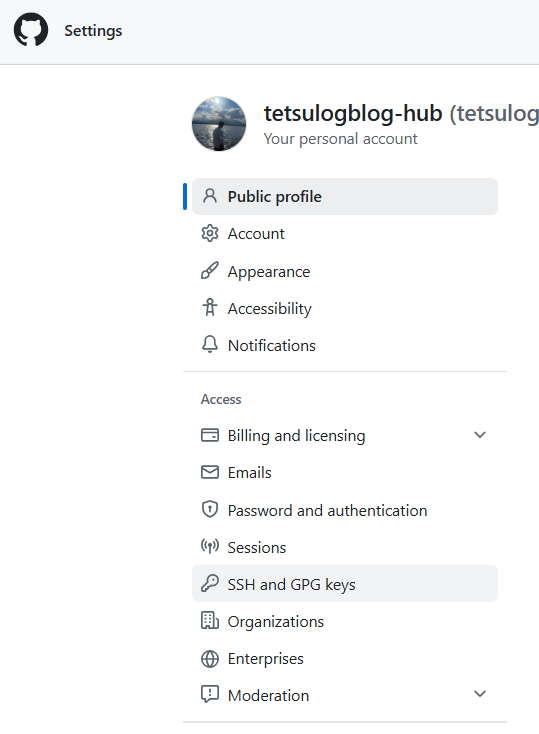
入れられましたか?入れられたら次に移りましょう。
4.紐づけと送信
サーバー内のフォルダとGitHubのリポジトリをリンクさせ、コードをアップロード(プッシュ)しましよう。
リポジトリを作成した直後のGitHub画面に表示されるURL(git@github.com:ユーザー名/リポジトリ名.git)を使用して接続します。
事前にプロジェクトのディレクトリを作成しておきましょう。そこに移動し、下記コマンドを実行します。
# 1. フォルダをGit管理にします
git init
# 2. GitHubの「住所」を登録します
# ※ git@github.com... の部分は、GitHubで作ったリポジトリのページから取得したURLに書き換えてください
git remote add origin git@github.com:ユーザー名/リポジトリ名.git
# 3. 万が一ブランチ名が「master」になっている場合に備え、名前を「main」に固定します
git branch -m main
# 4. 全ファイルを記録対象にします
git add .
# 5. 「最初の記録」として保存します
git commit -m "Initial commit"
# 6. GitHub(origin)のメインの枝(main)へ送信します
git push -u origin main
私自身これをやるだけでもめっちゃエラーを経験したので、メモみたいな感じでエラーの内容等を掲載しておきます。
| 発生したエラー | エラーの正体 | 解決のロジック |
| 許可がありません | システム専用の重いデータ(DB)に触ろうとした | .gitignore で管理対象から外す |
| Author unknown | 「誰が書いたか」の署名がなかった | git config で名前とメールを登録する |
| Rejected (fetch first) | GitHub側と手元の「歴史」がズレていた | git pull で一度歴史を同期させる |
| CONFLICT | 同じファイルの同じ場所が、双方で書き換わっていた | 手動で中身を整理して「仲直り」させる |
1. 権限エラー:システムデータの除外
- 注目すべき点:
db/フォルダ内の「許可がありません」というメッセージ。 - 解説: Dockerなどのデータベースが使う領域は、非常に強い権限で守られています。これらを無理にGitでバックアップしようとすると、エラーになるだけでなく、バックアップが巨大化してしまいます。
- ハンドリング:
.gitignoreという「無視リスト」を作成し、システムデータを除外して「自分の書いたコード(資産)」だけを守るようにしました。
2. 署名エラー:身元の証明
- 注目すべき点:
Please tell me who you are.というGitからの問いかけ。 - 解説: Gitは「変更の責任者」を記録するツールです。 誰が書いたかわからないコードは、ビジネスの現場では「信頼できないデータ」とみなされます。
- ハンドリング:
user.nameとuser.emailを設定し、自分の作業に責任を持つ(署名する)準備を整えました。
3. 歴史の不整合:同期の重要性
- 注目すべき点:
fetch first(先に取ってきて)という警告。 - 解説: GitHub上でリポジトリを作った際に自動生成されたファイルと、手元で作り始めたファイルが、「別々のタイムライン」として存在していました。
- ハンドリング:
--allow-unrelated-historiesというフラグを使い、別々に始まった2つの歴史を強引に一本の道に繋ぎ合わせました。
4. コンフリクト:人間の判断による統合
- 注目すべき点:
CONFLICTという文字と、ファイル内の<<<<<<<といった記号。 - 解説: 機械(Git)が「どちらが正しいか判断できない」状態です。
- ハンドリング: 人間の目で内容を確認し、不要な管理記号を消して、必要な設定(
db/の除外など)だけを抽出して保存しました。
お疲れ様です。ここまでお疲れ様でした。GitHubとの連携まで完了です。
ここからは全体の処理フローをつくっていきます。
全体処理フローのロジック(処理の手順)
以下が今回稼働させるシステムの詳細なステップになります。
前提を説明するのを忘れていたのですが、今回はニュースサイトから情報取得して、AIに要約してもらいブログの下書きに出力するというものになります。
- 情報取得: 定期的にRSSフィードを巡回し、最新の記事タイトル、URL、本文(スニペット)をフェッチします。
- 重複・不要データチェック: 取得したURLが既にDB(SQLite等)に存在しないか照合し、既知の情報は破棄します。
- ドラフト生成(AI連携): プロンプトに「DBから取得した情報」と「出力形式の指示(HTMLタグの使用等)」を載せ、生成AI APIへリクエストを投げます。
- 品質バリデーション(自動検品): 生成された記事に対し、文字数、NGワードの有無、フォーマット(HTML構造)が正しいかをプログラム側でチェックします。
- 再生成ループ: バリデーションに失敗した場合、AIに「どこが悪かったか」をフィードバックして、上限回数(例: 3回)まで再生成を依頼します。
- WordPress投稿: 基準をクリアした記事のみ、WordPress REST APIを通じて「下書き」として投稿します。
ちなみにこの処理フローは生成AIと会話しながら作ったものになります。
自分知らなくて実現できるかわからない技術手法についてはAIに聞くことをお勧めします。
出力される内容のファクトチェックは必要ですが、自分の実現したいことさえ説明できればいくつかの現実的な方法は教えてくれます。
作るだけならだれも損しませんし、自分の経験となるので実際にトライしてみるのが速いと思います。
AIを毛嫌いせずどんどん使っていくことで、わからないで止まっていたことがだんだんとわかるようになってきます。
締め
今回はここまでです。ご精読ありがとうございました。
次回はこのフローをもとに、プロトタイプの作成をしてみたいと思います。
プロトタイプなんて作って意味あんの?最初から本番用作って、スクラップ&ビルドすればよくない?
こんな声もあると思いますが、まずはフローが正しくかなどの全体把握は必要です!
その点についても次回深く触れていこうと思います。
次回もぜひ読んでいただけると幸いです。ではでは。

コメント