
こんにちは、てつです!
前回は、全体の処理フローを最小構成で動かすためのプロトタイプ作成をしました。
今回は、実際のニュースサイトから情報を取得し、記事を生成するところをやっていこうと思います!
前回の記事はこちら

RSS取得のロジック
今回は、RSSを利用してニュースを取得していきます。
RSSってなに?
一言で言えば「ウェブサイトの更新情報を効率よく受け取るための専用フォーマット」です。
通常、ウェブサイトは人間が読むためにデザインされていますが、RSS は「コンピュータ(プログラム)が読むため」のシンプルなデータ形式(XML)で書かれています。
今回やること
ライブラリの準備: RSS(XML形式)をPythonで扱いやすい形に分解してくれる feedparser を使います。
接続と解析: 海外サイト(The Hacker News)のRSS URLにアクセスし、最新の投稿データを読み込みます。
情報の抽出: 膨大なデータの中から、私たちがブログで使いたい「タイトル」「リンク(URL)」「記事の概要」の3つだけを抜き出します。
表示確認: ターミナルに正しく情報が出力されるか確認します。
準備:ライブラリのインストール
次章に入る前にライブラリの準備だけやっていこうと思います。
RSSを解析するための標準的なライブラリ feedparser をインストールします。ターミナルで以下のコマンドを実行します。
pip install feedparser
できましたか?そしたら次章から実装していきましょうか。
RSSリーダーで最新情報を取得する
実装のロジック(処理の手順)
- ソースのリスト化: 取得したい3つのサイトの名前とRSS URLをペア(辞書形式)にしてリストにまとめます。
- 巡回(ループ)処理: リストに入れたURLを順番に読み込み、それぞれの最新記事を取得します。
- データの統合: 各サイトから抽出した「タイトル」「リンク」「概要」「サイト名」を一つの大きなリストに集約します。
- エラーハンドリング: 特定のサイトで読み込みエラーが起きても、プログラム全体が止まらないように保護します。
取得したい3つのサイトの紹介をしたいと思います。以下の表にまとめましたのでご参照ください。
| サイト名 | 特徴 | RSS URL |
| The Hacker News | 速報性が極めて高く、世界中の攻撃事例を網羅 | https://feeds.feedburner.com/TheHackersNews |
| BleepingComputer | ランサムウェアや OS の脆弱性に関する詳細解説に強い | https://www.bleepingcomputer.com/feed/ |
| Dark Reading | エンタープライズ(企業)向けの深い分析記事が豊富 | https://www.darkreading.com/rss.xml |
表を見て察した方もいると思います。今回作るサイトは、セキュリティ系の情報のまとめになります。
なぜセキュリティかというと、私はセキュリティ系の運用の現場働いていることと自分でブログやサーバーを運営していこうとしている身として、最新の情報を追うためになります。
海外発の情報は、日本語に翻訳されるまでタイムラグがあるため、海外初の情報を翻訳してそのラグを埋めること目的としています。
テストコードは以下のようになります。ご参考にしてください。
import feedparser
# 1行解説: 取得対象のサイト名とRSS URLを辞書のリストとして定義します
RSS_SOURCES = [
{"name": "The Hacker News", "url": "https://feeds.feedburner.com/TheHackersNews"},
{"name": "BleepingComputer", "url": "https://www.bleepingcomputer.com/feed/"},
{"name": "Dark Reading", "url": "https://www.darkreading.com/rss.xml"}
]
def fetch_all_security_news(limit_per_site=2):
"""
登録されたすべてのサイトから最新ニュースを取得する関数
"""
all_news = []
# 1行解説: 登録したサイトのリストを一つずつ順番に処理(ループ)します
for source in RSS_SOURCES:
print(f"{source['name']} から取得中...")
# 1行解説: サイトのURLを解析して記事データを読み込みます
feed = feedparser.parse(source['url'])
# 1行解説: 各サイトから指定した件数(デフォルトは2件)だけ記事を抽出します
for entry in feed.entries[:limit_per_site]:
news_data = {
"site_name": source['name'], # どのサイトの情報か識別するために保存
"title": entry.title, # 記事のタイトル
"link": entry.link, # 記事のURL
"summary": entry.summary # 記事の概要(AIへのインプット用)
}
all_news.append(news_data)
return all_news
# 1行解説: このファイルが直接実行された時だけテスト動作を行います
if __name__ == "__main__":
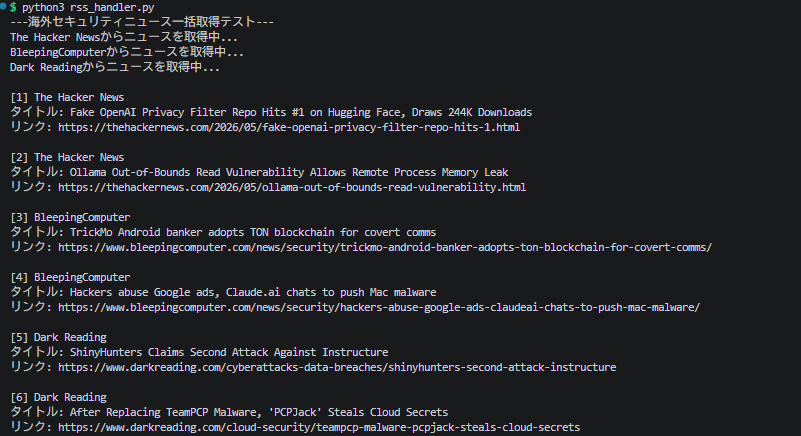
print("--- 海外セキュリティニュース一括取得テスト ---")
results = fetch_all_security_news()
for i, news in enumerate(results, 1):
print(f"[{i}] [{news['site_name']}] {news['title']}")
print(f"URL: {news['link']}\n")
どうですか?私はこんな感じになりました。少しテストコードと結果の表示の仕方が違うので表示が違うかもしれませんね。でもエラーが出ずに、サイト名とURLが表示されれば成功です。
ここまでくれば情報源の準備は完了です。
これまで作ったものと連携
複数のニュースが取れるようになったので、前回作った司令塔(proto_main.py)の役割を以下のように更新します。
- ニュースの選択: 取得した 6 件の中から、一番インパクトのありそうな「1 件目」をピックアップします。
- AI への情報伝達:
rss_handlerで取れたtitle(タイトル)とsummary(概要)を AI のプロンプト(命令文)に埋め込みます。 - 専門家人格の注入: ただの翻訳ではなく、ペルソナを設定することで専門家のコメントを入れ込む。
早速前回作ったファイルを更新していきましょう。
念のため更新部分以外のテストコードとプロンプトを張り付けておきますね。
#prompts.py
# 1行解説: セキュリティニュースをブログ形式に変換するための命令文(プロンプト)を定義します
SECURITY_BLOG_PROMPT = """
あなたはセキュリティエンジニア、分析アナリストチームのリーダーです。
以下の英語ニュースを読み、日本のIT担当者向けにブログ記事をHTML形式(h2, pタグ等)で書いてください。
【ニュースタイトル】
{title}
【ニュースの概要】
{summary}
【執筆ルール】
1. 最初に「なぜこの記事が重要か」を1文で述べること。
2. 専門用語を日本のエンジニアが普段使う言葉で解説すること。
3. 最後にセキュリティエンジニア、分析アナリストとして、現場が取るべき具体的な初動対応を提案すること。
4. 出力は WordPress のエディタにそのまま貼れる HTML 形式(h2, p, ul, li)にすること。
"""
#prot_main.py
import os
from pathlib import Path
from dotenv import load_dotenv
from prototype_core import generate_article
from wp_handler import post_to_wordpress
from rss_handler import fetch_all_security_news
from prompts import SECURITY_BLOG_PROMPT
env_path = Path(__file__).resolve().parent.parent / ".env"
load_dotenv(dotenv_path=env_path)
def run_automation():
print("ニュース取得中")
news_list = fetch_all_security_news(limit_per_site=1)
if not news_list:
print("ニュースが取得できませんでした")
return
target = news_list[0]
print(f"ターゲットニュース: {target['title']}")
formatted_prompt = SECURITY_BLOG_PROMPT.format(
title=target['title'],
summary=target['summary']
)
print("AIによる執筆と翻訳開始")
content = generate_article(formatted_prompt)
print("WordPressへ下書き投稿中")
success, response = post_to_wordpress(
os.getenv("WP_URL"),
os.getenv("WP_USER"),
os.getenv("WP_PASS"),
f"[海外速報]{target['title']}",
content
)
if success:
print("記事の投稿に成功しました。")
else:
print(f"記事の投稿に失敗しました。{response}")
if __name__ == "__main__":
run_automation()
出力結果は以下の通りになりました。
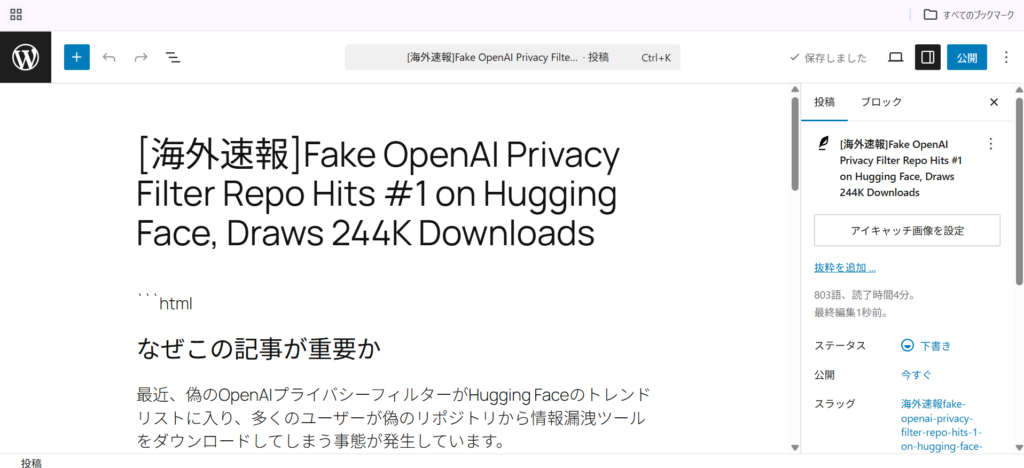
淡白だし、タイトルは英語だし、内容も薄いですが、一応情報を取得して下書きに投稿までいけました。
ここまでくればあとはプロンプトの調整や情報サイトの選定などの細かい部分になってくるかと思います。
とりあえず、ここまでお疲れさまでした。心臓部分の完成ですね!
まとめ
今回は、実際の海外セキュリティニュースサイトからRSSを利用して最新情報を取得し、それをAIに渡してブログ記事を生成、WordPressへ下書き投稿する流れを実装しました。
前回のダミーデータとは違い、本物のリアルタイムなニュースが自分のプログラムを経由してブログに投稿された瞬間は、ちょっと感動しましたよね笑
これで、ブログ半自動化システム自体ほぼ完成です!
出力結果を見てわかる通り、記事の内容が少し淡白だったり、タイトルが英語のままだったりと、ブログとして公開するにはまだまだプロンプトの調整が必要ですが、仕組みさえできてしまえばあとはチューニングの問題です。
ここまで本当にお疲れさまでした。
次回は、さらに磨き上げるために、AIのプロンプトを調整して記事の質を上げたり、特定のキーワードを持つニュースだけを厳選して取得するように工夫したりしていこうと思います。
いよいよ実用的なツールへと進化させていきますので、次回も楽しみにしていてください!
最後まで読んでいただき、ありがとうございました!
コメント