
こんにちは、てつです!
今回は、監視体制の「心臓部」である Prometheus(プロメテウス) を立ち上げます。
前回、Node ExporterでCPUやメモリの使用率を見れるという段階までやりました。ただ、人間が見るには少し不便な状態でしたね。
しかし、この人にとっては見ずらい数字の羅列は、Prometheusにとっては扱いやすいデータ形式になっているんです!
例のごとく、Docker-Composeを使ってPrometheusを導入して管理画面を見れるところまで今回はやっていこうと思います!
ではさっそくやっていきます!
Prometheus(プロメテウス)について
前回導入したNode Exporterは、データを測る係でしたね。
それに対して、今回導入するPrometheusは、サーバーの挙動をミリ秒単位で記録し続ける「高精度なフライトレコーダー」のような存在です。
| コンポーネント | 役割 | 技術的な動き |
| Node Exporter | 現場のレポーター | OSの低レイヤー(CPU/メモリ/ディスク)から生データを抽出し、標準化します。 |
| Prometheus Server | 本部の分析官 | 定期的なポーリング(巡回)により、各現場から自発的にデータを吸い上げます。 |
| TSDB (時系列DB) | 台帳(元帳) | 全てのデータを「いつ、何が起きたか」という時間軸で、高速に蓄積・最適化します。 |
また、従来のツールは、異常時にサーバー側から通知を送らせる「プッシュ型」が主流でした。
しかしこれでは、サーバーが「通知すら送れないほど致命的なダウン」をした際に、沈黙の理由がわかりません。
Prometheusが自ら巡回(プル型)することで、「応答がない=異常発生」という事実を、外部から客観的に、かつ即座に判定できるのです。
なんとなくPrometheusの役割はわかりましたか?
次章は構築ステップについてのイントロダクションになりますので、ある程度理解してから次章を見ると理解が深まると思います!
構築ステップ
以下の4ステップで進めていこうと思います。
1.監視専用ディレクトリの作成
- 既存の
serverのディレクトリ 内にmonitoringフォルダを作り、設定ファイルを整理します。
2.Node Exporter(集荷係)の設置→前回構築済み
- サーバーのCPUやメモリ使用率を「Prometheusが読める形式」に変換して吐き出すツールを立てます。
3.Prometheus(倉庫)の設定
- 「Node Exporterから、5秒おきにデータを取ってきて!」という指示書(
prometheus.yml)を書きます。
4.Docker Composeで一括起動
- 全てを連動させて動かします。
流れはわかりましたかね?では実践に取り掛かっていきましょう!
実践編
ディレクトリの作成
まず、ディレクトリを作っていきましょう。
下記コマンドを実行してディレクトリを作ります。
※今回はすでにあるサーバ監視系のディレクトリに移動して作業を開始しております。
mkdir -p monitoring/prometheus問題なく作れたら次に移ります。
Prometheusの設定ファイル作成
これが「誰のデータを、どれくらいの頻度で集めるか」を決める重要なファイルです。
下記コマンドを実行して設定ファイルを編集します。
nano monitoring/prometheus/prometheus.yml編集の画面に遷移したでしょうか?できたら以下の内容を貼り付けます。
global:
scrape_interval: 5s # 5秒おきにデータを取得(変化が見えやすい5秒がおすすめ)
scrape_configs:
- job_name: 'node_exporter'
static_configs:
- targets: ['node-exporter:9100'] # 集荷係(Exporter)の居場所を指定なぜその設定が必要なのか?
scrape_interval は、健康診断の頻度のようなものです。短くするとリアルタイム性が増しますが、サーバーの負荷も少し上がります。個人開発なら5秒〜15秒がベストバランスです!
docker-compose.yml への追記
既存の docker-compose.yml に、監視用のコンテナ情報を追加していきます。
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./monitoring/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
command:
- '--config.file=/etc/prometheus/prometheus.yml'
ports:
- "9090:9090"
restart: always各項目の深掘り解説(なぜこれが必要なのか?)
volumes (ボリューム)
- 解説: 「サーバー上の設定ファイル」と「コンテナの中の設定ファイル」を紐付けています。
- 理由: コンテナの中にあるファイルは、コンテナを消すと一緒に消えてしまいます。サーバー上のファイルを読み込ませるようにしておくことで、設定を変更したいときにサーバー側のファイルを書き換えるだけで済むようになります。
command (コマンド)
- 解説: Prometheusに対して「設定ファイルはこの場所にあるから、これを読んで動いてね!」と明示的に伝えています。
- 理由: 先ほどの
volumesで同期した場所を指定することで、私たちが作ったprometheus.ymlの指示通りに監視を始めてくれるようになります。
ports (ポート)
- 解説:
左側:右側という書き方をします。左側が「実際のサーバーのポート」、右側が「コンテナの中のポート」です。 - 理由: Prometheusは標準で 9090番 を使って画面を表示します。ブラウザで
http://サーバーIP:9090と打ったときに、このコンテナに繋がるように玄関を開けているわけです。
restart: always (再起動設定)
- 解説: もしエラーで止まったり、サーバー本体を再起動したりしても、勝手に立ち上がって監視を再開してくれます。
- 理由: 監視ツール自体が止まったままでは意味がないため、運用監視においては必須の設定です。
上記の設定は終わりましたか?設定が終わったら、いよいよ起動です!
下記コマンドを実行してみましょう!
sudo docker compose up -d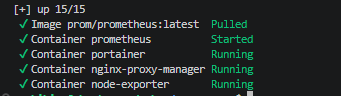
このようにコンテナが立ち上がったらほぼほぼ成功です。あとは、「IPアドレス:9090」をブラウザにいれてみてください!
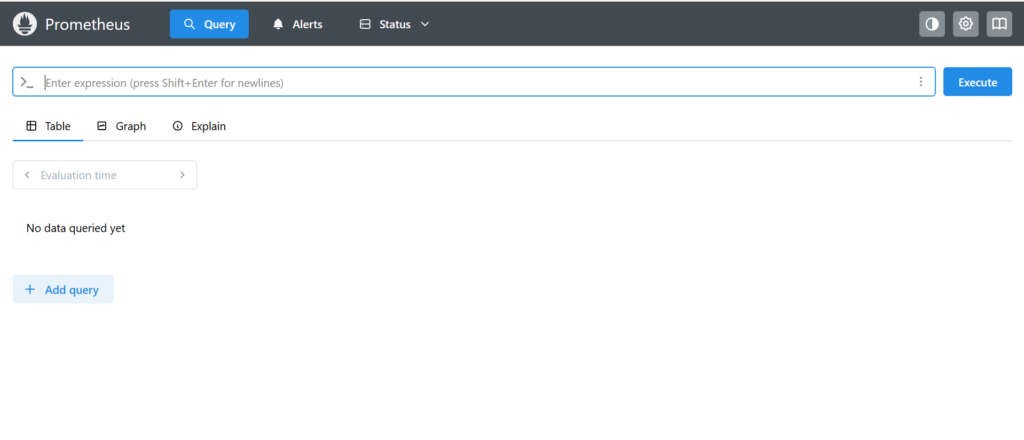
この画面が出たら成功です!
最後に、「Node Exporterからデータを吸い上げられているか」をチェックして、今回の構築を締めくくります!
中央の検索バーに「node_memory_MemAvailable_bytes」を入れてみます!
Prometheus画面上部のメニューから 「Status」 をクリックし、「Targets」 を選択してください。
そこに node_exporter という項目があり、「UP(緑色)」 になっていれば、データ収集は正常です。

ステータスがUPになってますね!これで視覚化はできましたね!
今回の構築実践はここまでです!ありがとうございました!
まとめ
ここまで読んでくださりありがとうございました!
今回は、PrometheusのデプロイとNode Exporterとの連携に成功しました!
可視化の第一歩を踏み出せました。 node_memory_MemAvailable_bytes というメトリクス(指標)を用いて、メモリの空き容量を可視化出てきてましたよね。
サーバーを「動かして終わり」ではなく、その状態を「客観的な数字で把握できる」環境にやっとなりました。
ただ、今のPrometheusの画面もエンジニアっぽくて格好いいですが、実用性(一目で異常に気づけるか)という点では、まだ改善の余地がありますよね。。
そこで、次回は、いよいよ「Grafana(グラファナ)」を導入します。
何ができる?: 今の無機質なグラフを、SF映画に出てくるような「洗練されたコックピット」に変身させます。
なぜやる?: CPU、メモリ、ディスク、ネットワークの状況を1枚のボードに集約し、ひと目で「異常なし!」と判断できるようにするためです。
次回が視覚的にも技術的にも個人的に楽しみなところなので是非次回もよろしくお願いします!


コメント